Documentation Index
Fetch the complete documentation index at: https://training-docs.cerebras.ai/llms.txt
Use this file to discover all available pages before exploring further.
What is a Read Hook?
We use read hooks to convert from different input formats to HDF5 format. Pre-built hooks are provided for standard input formats and masking schemes.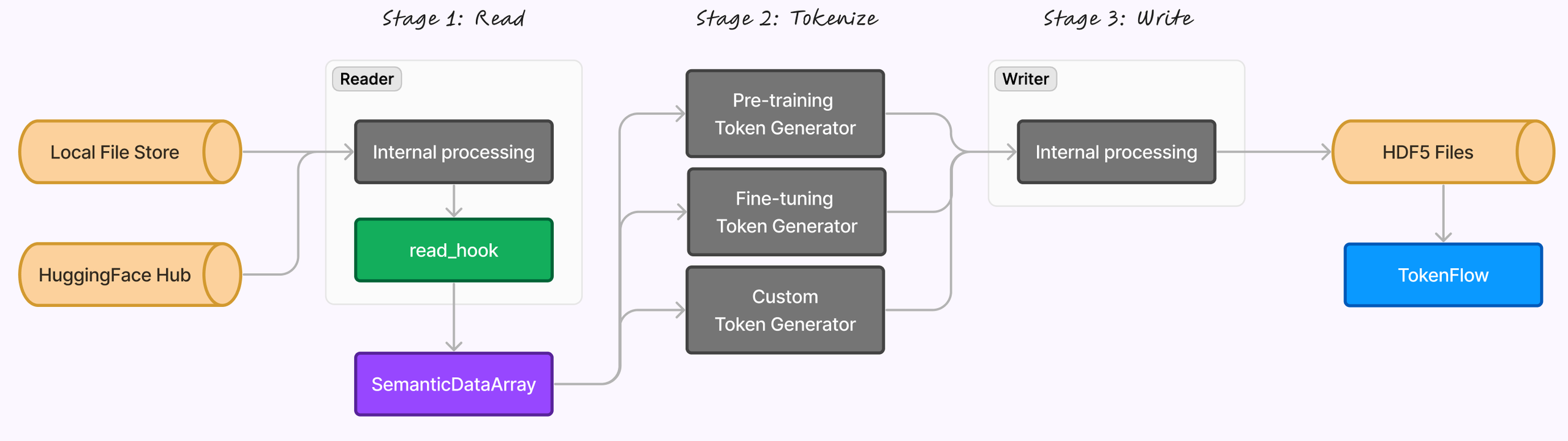
Read
Data is sourced from either a local file store or the Hugging Face Hub and processed by the Reader module, which applies a
read_hook before converting the data into a SemanticDataArray. Tokenize
The data is then transformed using one of three token generators—pre-training, fine-tuning, or custom—depending on the use case.
- Seamlessly integrate local and HuggingFace data sources
- Customize data loading for specific tasks
- Optimize preprocessing efficiency
- Enhance overall model performance
Fine-tuning LLaVA Hook
This read hook processes conversation data to format it for fine-tuning LLaVA models. It looks for conversation turns, optional system prompts, and images. It requires keys for conversation data and image paths.Pretraining Text Hook
This read hook extracts and processes plain text data for reading tasks. It requires a key to extract text from input data.Pretraining Image Captions Hook
This read hook prepares data for image captioning pretraining tasks by extracting image paths and captions.NLG Hook
This read hook processes natural language generation (NLG) data, organizing context and completion information into a structured format. It requires context and completion keys.Prompt Completion Text Hook
This read hook formats prompt and completion text into a structured list. It requires prompt and completion keys.Chat Hook
This read hook transforms chat data into a semantic data array, distinguishing between user and assistant roles. Assumes data is in conversation format and requires a key for multi-turn content if the data is not in OpenAI ChatML format.DPO Hook
This read hook structures data for Direct Preference Optimization (DPO) tasks, organizing prompts, chosen responses, and rejected responses into semantic data array. Requires keys for prompt, chosen, and rejected data. The implementation can be found here.Prompt Completion Chat Hook
This read hook processes prompt and completion data as a single turn chat and creates a semantic data array format. The implementation can be found here.Fine-Tuning Image Captions Hook
Processes fine-tuning image captions data into a semantic data array format. Requires keys for image and caption data. The hook implementation can be found here.Fine-Tuning LLaVA Hook Prompt Completion
This read hook transforms conversation data for fine-tuning LLaVA, alternating between prompt and completion roles. Requires keys for conversation data and image paths. The hook implementation can be found here.Important Considerations
-
Handling keys to read data: The
read_hook_kwargsproperty must have data keys with the suffix_keyto segregate these from other parameters forread_hook_kwargs. These keys will be exclusively used to read data from the input while other parameters which are not data keys will be used to create semantic data array from the read hooks. - Space Handling: When combining custom regions, the data processor does not add any spaces or separators between the regions. Space handling must be managed within the read hooks. When creating custom semantic regions, ensure there is a leading space at the start of each region (except the first) to prevent the merging of words from neighboring regions.
- Multimodal Datasets: When working with multimodal datasets, if images are provided as URLs, the hooks should download the images and generate image paths to be used by the multimodal models.
-
Separator Handling With Prompt Completion Read Hook: The token generator adds a separator token between
promptandcompletionsemantic regions. The tokenizer’ssep_tokenattribute is used as a separator token if present; else we use<|sep|>.