Model Description
DINOv2 is a self-supervised vision transformer model by Meta that learns high-quality image representations without needing labeled data. It builds on the success of DINO by introducing architectural and training enhancements that deliver state-of-the-art performance across various computer vision tasks, including classification.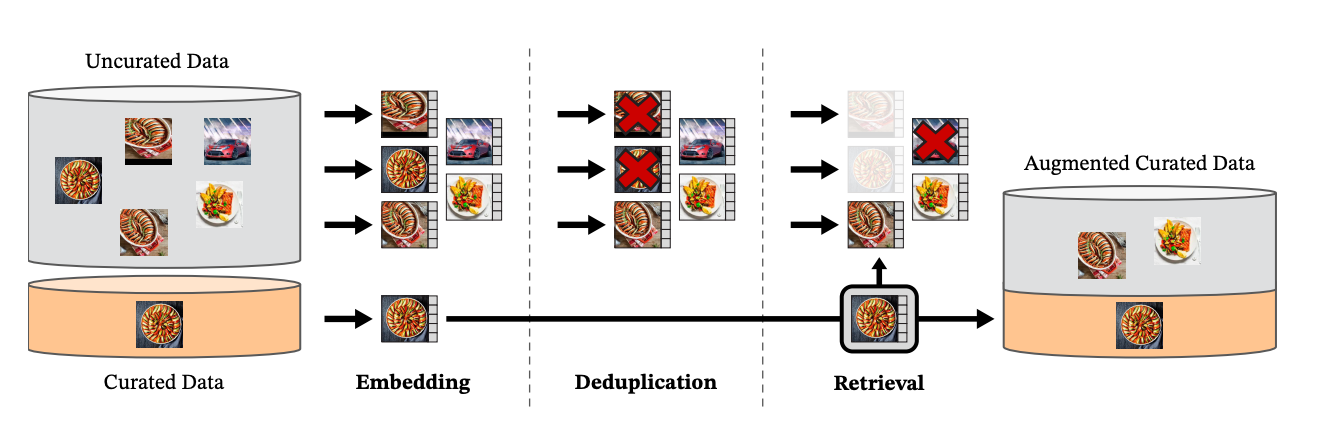
DINOv2 data processing pipeline, from Oquab et al 2023.
Code Structure
The code for this model is located in thedino directory within ModelZoo. Here’s how it’s organized:
-
configs/: Contains YAML configuration files. -
scripts/: Contains scripts for various workflows, including checkpoint conversion and image resizing. -
model.py: The implementation of the DINOv2 model. -
DinoImageDataProcessor.py: Data processor for DINOv2.
Available Configurations
Model Input Tensor Specifications
The tables below outline the expected input tensor formats for pretraining and fine-tuning. These formats are based on the configurations listed in the Available Configurations section above. If you are using a custom configuration, you can check the tensor specifications by running:- Pretraining
- Finetuning
About this Implementation
This implementation of DINOv2 uses thegeneric_image_encoders architecture as its backbone. You can find the model architecture details in its directory.
Differences Between Our Implementation and Meta’s
Unlike Meta’s version, which includes KoLeo loss, this implementation only includes DinoDistillationLoss and iBOTPatchLoss, which was introduced in DINOv2. Pretrained models from Meta and Hugging Face only include the backbone, meaning they cannot be used for continuous pretraining and are limited to downstream tasks. In contrast, our implementation provides everything needed for continuous pretraining.Workflow
In this workflow we’ll demonstrate how to get started using DINOv2, inlcuding for pretraining, continuous pretraining, and finetuning tasks.This workflow utilizes the ModelZoo CLI. For a list of all commands, please visit our CLI page.
1
Prerequisites and Setup
Before getting started, ensure that you’ve gone through our setup and installation guide.Next, create a dedicated folder for assets (configs, data) and generated files (processed data files, checkpoints, logs, etc.):
- Pretraining
- Continuous Pretraining
- Finetuning
Copy the sample model config for pretraining into your folder.
2
Data Preparation
Our implementation of DINOv2 supports all torchvision datasets. In our internal testing, we used ImageNet1K. To get started, set the dataset path to where your torchvision dataset is stored, ensuring it conforms to the torchvision standard. For more information on how to prepare datasets using Once your data directory is ready, modify the
torchvision, please visit our guide here.Once completed, your dataset directory should look as follows:root parameter under dataset in the model config to point to the desired dataset location.3
Running the Model
- Pretraining
- Continuous Pretraining
- Finetuning
Run the pretraining process using the provided configuration.
- CLI
- run.py
Advanced Use Cases
In addition to the workflows outlined above, we provide a number of scripts for more advanced and experimental use cases.Adjusting Image Size
You can continue training from an existing DINOv2 checkpoint while adjusting parameters such as image size. For this purposes, we provide thechange_image_size.py to modify the checkpoint and config.
Configuring Per-Layer Learning Rate Schedulers
As part of our DINOv2 model offering, we provide a script for generating a config file that includes learning rate schedulers, following the approach used in Meta’s original implementation of the model. Users can modify the learning rate settings to experiment with different schedules, but we recommend adhering to Meta’s specifications for optimal results. For a detailed explanation of Meta’s training methods for DINOv2, please refer to the paper. This script should be used with the reference implementation config that is provided. It will output a configuration similar toparams_dinov2_large_224_bs1024_cszoov2.yaml.
To run the script:
To use Meta’s predefined learning rate schedulers without modifications, simply specify only the
input_file_name and output_file_name flags.