Overview
This tutorial teaches you about Cerebras essentials like data preprocessing and training scripts, config files, and checkpoint conversion tools. To understand these concepts, you’ll fine-tune Meta’s Llama 3 8B on a small dataset consisting of documents and their summaries. In this quickstart guide, you will:- Setup your environment
- Pre-process a small dataset
- Port a trained model from Hugging Face
- Fine-tune and evaluate a model
- Test your model on downstream tasks
- Port your model to Hugging Face
In this tutorial, you will train your model for a short while on a small dataset. A high quality model requires a longer training run, as well as a much larger dataset.
Prerequisites
To begin this guide, you must have:- Cerebras system access. If you don’t have access, contact Cerebras Support.
- Completed setup and installation.
Workflow
1
Create Model Directory & Copy Configs
First, save the working directory to an environment variable:Then, create a dedicated folder to store assets (like data and model configs) and generated files (such as processed datasets, checkpoints, and logs):Next, copy the sample configs into your folder. These include model configs, evaluation configs, and data configs.
We use
cp here to copy configs specifically designed for this tutorial. For general use with Model Zoo models, we recommend using cszoo config pull. See the CLI command reference for details.2
Inspect Configs
Before moving on, inspect the configuration files you just copied to confirm that the parameters are set as expected.
Model Config
Model Config
To view the model config, run:You should see the following content in your terminal:These parameters specify the full architecture of the Llama 3 8B model and help define a Trainer object for training, validation, and logging semantics.If you are interested, learn more about model configs here, or dive into how to set up flexible training and evaluation. You can also follow end-to-end tutorials for various use cases.
Evaluation Config
Evaluation Config
To view the evaluation config, run:You should see the following content in your terminal:This file lets you evaluate your model via the multiple choice (non-generative) eval harness task
winogrande on a single CSX system.If you are interested, you can learn more about validating models using the Eleuther or BigCode Evaluation Harness in our documentation.Data Config
Data Config
To view the data config, run:You should see the following content in your terminal:If you are interested, you can read more about the various parameters and pre-built utilities for preprocessing common data formats. You can also follow end-to-end tutorials for various use cases such as instruction fine-tuning and extending context lengths using position interpolation.
3
Preprocess Data
Use your data configs to preprocess your “train” and “validation” datasets:You should then see your preprocessed data in
finetuning_tutorial/train_data/ and finetuning_tutorial/valid_data/ (see the output_dir parameter in your data configs).An example of “train” looks as follows:Inspect Preprocessed Data (optional)
Inspect Preprocessed Data (optional)
Once you’ve preprocessed your data, you can visualize the outcome:In your terminal, you will see a url like 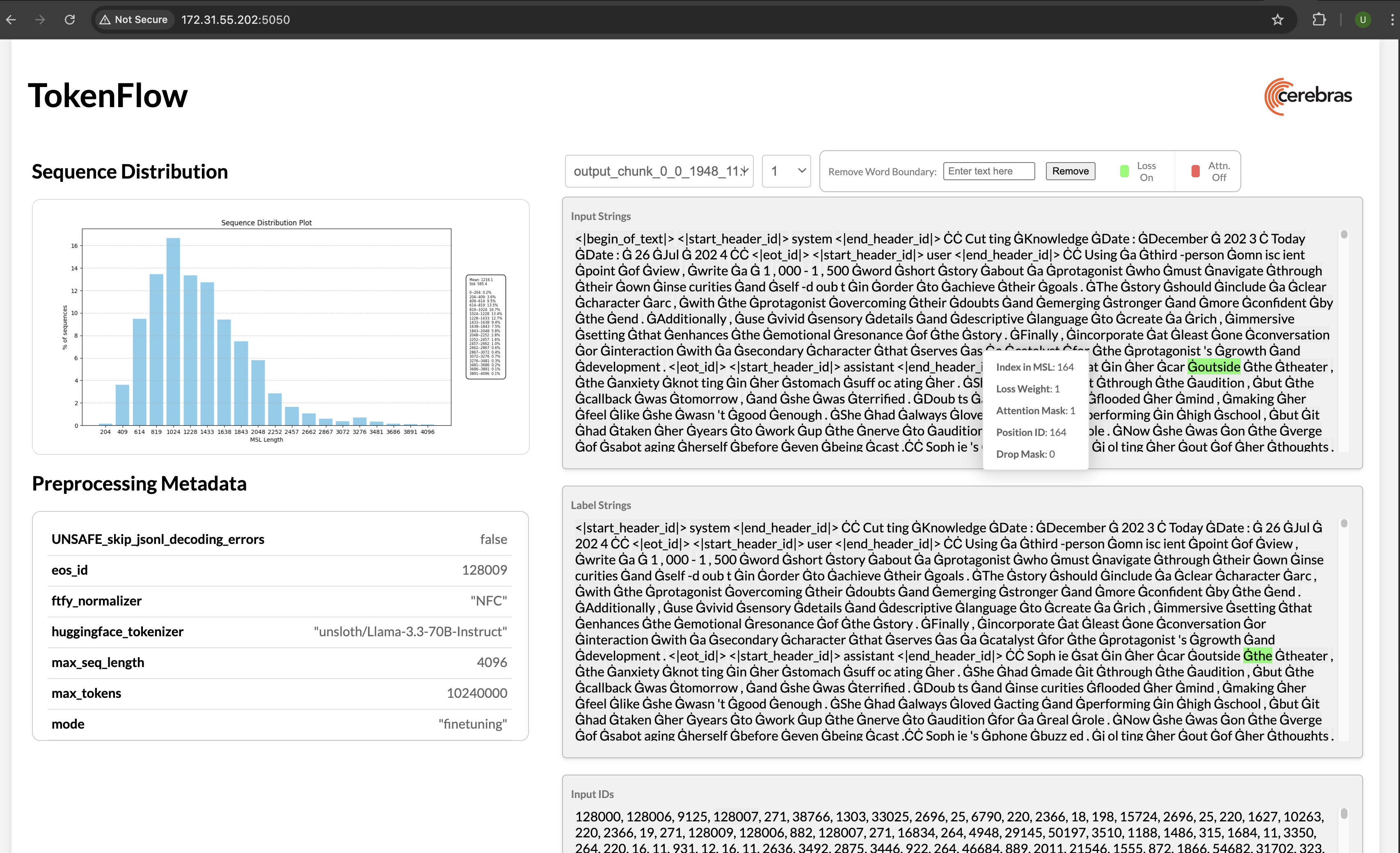
http://172.31.48.239:5000. Copy and paste this into your browser to launch TokenFlow, a tool for interactively visualizing whether loss and attention masks were applied correctly:4
Download Checkpoint and Configs
Create a dedicated folder for the checkpoint and configuration files you’ll be downloading from Hugging Face.You can either fine-tune a model from a local pre-trained checkpoint or (as in this tutorial) from Hugging Face.First, download checkpoint and configuration files from Hugging Face using the commands below. For the purposes of this tutorial, we’ll be using McGill’s Llama 3-8B-Web, a finetuned Meta-Llama-3-8B-Instruct model.This will save two files in the
finetuning_tutorial/from_hf directory:- config.json: The model’s configuration file.
- pytorch_model.bin: The model’s weights.
5
Convert Checkpoint and Configs
You can now convert the files to a format compatible with Model Zoo:Your
finetuning_tutorial/from_hf folder should now contain:pytorch_model_to_cs-2.3.mdl: The converted model checkpoint.config_to_cs-2.3.yaml: The converted configuration file.
ckpt_path in your finetuning_tutorial/model_config.yaml to the location of this converted checkpoint.6
Train and Evaluate Model
Set Train your model by passing your updated model configs, the location of important directories, and python packages to a run script. Click here for more information.You should then see something like this in your terminal:Once training is complete, you will find several artifacts in the
train_dataloader.data_dir and val_dataloader.data_dir in your model config to the absolute paths of your preprocessed data:finetuning_tutorial/model folder (see the model_dir parameter in your model config). These include:- Checkpoints
- TensorBoard event files
- Run logs
- A copy of the model config
Inspect Training Logs (optional)
Monitor your training during the run or visualize TensorBoard event files afterwards:7
Run Evaluation Tasks
After training, you can test your model on downstream tasks:Your output logs should look something like:
8
Port Model to Hugging Face
Once you train (and evaluate) your model, you can port it to Hugging Face to generate outputs:This will create both Hugging Face config files and a converted checkpoint under
finetuning_tutorial/to_hf.9
Validate checkpoint and configs (optional)
You can now generate outputs using Hugging Face:
As a reminder, in this quickstart, you did not train your model for very long. A high quality model requires a longer training run, as well as a much larger dataset.
Conclusion
Congratulations! In this tutorial, you followed an end-to-end workflow to fine-tune a model on a Cerebras system and learn about essential tools and scripts. As part of this, your learned how to:- Setup your environment
- Pre-process a small dataset
- Port a trained model from Hugging Face
- Fine-tune and evaluate a model
- Test your model on downstream tasks
- Port your model to Hugging Face
What’s Next?
- Learn more about data preprocessing
- Learn more about the Cerebras Model Zoo and the different models we support